
Page restricted | ScienceDirect
Page restricted | ScienceDirect
Your Browser is out of date.
Update your browser to view ScienceDirect.
View recommended browsers.
Request details:
Request ID: 860966c13bbf10aa-HKG
IP: 49.157.13.121
UTC time: 2024-03-07T09:01:31+00:00
Browser: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36
About ScienceDirect
Shopping cart
Contact and support
Terms and conditions
Privacy policy
Cookies are used by this site. By continuing you agree to the use of cookies.
Copyright © 2024 Elsevier B.V., its licensors, and contributors. All rights are reserved, including those for text and data mining, AI training, and similar technologies. For all open access content, the Creative Commons licensing terms apply.
什么是AMM(自动做市商),它为何如此受欢迎? - 知乎
什么是AMM(自动做市商),它为何如此受欢迎? - 知乎切换模式写文章登录/注册什么是AMM(自动做市商),它为何如此受欢迎?慧说区块链区块链前沿技术应用科普DeFi领域中的去中心化交易所能够走入人们的视野并迅速崛起的一个核心原因是引入了自动做市商的模式。1、什么是AMM?自动做市商即AMM,它能根据简单的定价算法自动计算出买卖价格,我们可以把它想象为一个进行买卖交易的机器人。他解决了传统交易所过渡到DEX(去中心化交易所)中出现的成本和效率问题。在展开论述前,我们先认识几个名词。AMM(Automated Market Maker) 自动做市商Liquidity 流动性,指各项资产的数量分布情况Liquidity Pool 流动性池,指各类资产所对应的资金池LP(Liquidity Provider) 流动性提供者,向流动性池内添加对应资产的用户Order Book 订单薄,中心化交易所的做市方式Slippage 滑点,指下单价格和最后成交价的差额比例传统的中心化交易所上的订单薄做市模式在区块链上运作起来出现了很多问题,所以就创新了AMM自动做市商。2、中心化交易所做市模式为了更好理解这一创新,我们先介绍中心化交易所的做市模式。在传统的交易所中做市,不管是股市还是加密资产交易所,采用的都是订单薄模式。订单薄记录着买卖双方对资产的报价情况。在Order Book中有两个角色,第一个是做市商,即挂单者,也叫Maker;另一个是交易者,即吃单者,也叫Taker。专业的做市商(Maker)会同时在交易所的买卖两个方向挂单,并且根据市场的波动性调整报价,为交易所提供流动性。简单来说做市商就是提供报价和流动性的人。在做市行为中,挂单的资产数量称为流动性,提供资产的人称为流动性提供者。LP提供流动性后,还需要为资产提供一个价格,这样才算是完成做市。通常情况下,流动性与价格的提供者都是同一个人。如果一个交易所没有做市商做市,或者很少做市商,交易者想要交易就会面临没有流动性的情况。缺乏流动性就意味着会造成高滑点交易,即交易者最终成交价格与看到的价格有很大差距,这会导致整个市场交易积极性不高。为了提高交易的流动性,中心化交易所通常会吸引做市商来进行做市操作。专业的做市商会在当前价格附近提供尽可能多的流动性,以供交易者交易,然后以非常高的频率进行撤单和挂单操作,以避免产生损失。做市商最终目的是获利,与此同时他们的交易活动也为交易者创造了流动性,降低了交易滑点。许多做市商都是专业的团队或者机构,他们拥有充足的资金和强大的技术支持,对市场敏感度高,可以实时对做市策略进行调整,以避免损失。在中心化交易所做市除了有一定难度和门槛问题外,中心化交易所还一手掌管着用户的资产和数据存储,不仅会暴露个人隐私,交易和代币的流通也存在不够透明的问题。3、AMM模式的价格机制区块链的崛起无疑给传统中心化交易所存在的问题提供了一个好的解决方式,特别是以Eth为代表的可编程的去中心化区块链的出现,有一部分人相信去中心化技术所带来的资产安全保障、无需信任的第三方,以及数据的公开透明,DEX变走入了人们的视野。早期DEX也套用了订单薄模式,但没能发展起来,随后AMM模式,逐渐成为主流。在AMM模式中,流动性由LP来提供。LP将自有资产按比例存入池子中为交易提供流动性,这个池子称为流动性池。当交易者进行交易时,实际上是与流动性池进行交易,交易价格由AMM模型根据参数自动生成。流动性池可以分为三类:恒定资产比例池,两种资产比例在50/50;混合资产池,支持3种及以上资产;加权池,多种资产比例。恒定资产比例池最常见,比如BTC/USD,ETH/USD。当用户持有ETH,想兑换BTC时,就需要进行两次交易。混合资产池方案(Curve)采用了混合资产池方案来解决这一问题,在流动资产池中放入3种资产。加权池的资产比例方案可以调节,比如Balancer可以在30/70等不同比例之间进行选择。LP提供流动后获得相应的LP Token,相当于一种存款凭证。用户根据自己资金比例所分得的交易手续费会累积到LP Token的价值中,有些平台还提供平台原生代币的奖励。用户提供流动性获得收益的行为被称为流动性挖矿。有了流动性之后还不够,要完成做市交易还需要提供报价,那么AMM是如何生成价格的呢?不同AMM模型,他们的价格计算共识也有所不同,大致可以分为恒定乘积做市商(cpmm)、恒定和做市商(csmm)、恒定平均值做市商(cmmm)等几类。目前普及类较高的是恒定乘积做市商。Uniswap使用的就是恒定乘积做市商+恒定资产比例池(50/50)。恒定乘积做市商基于函数x*y=k,x、y分别代表流动池中两种资产的数量,他们的乘积是恒定的常数k。当代币x供给增加时,y代币的供给就必须减少,反之亦然。当当价格变动越来越大时,两端会接近无穷大。4、AMM模式的优点和不足AMM的自动化模式使得做市操作变得非常简单,并且在去中心化的背景下其监管面非常小,提供流动性也很便捷,任何用户都可以以任何资金量参与。流动性挖矿奖励也激励了用户提供流动性,提供良好的闭环。不过,AMM模型也没有达到完美程度。它存在一些局限性,体现在三方面:第一, 无常损失的风险。在AMM中,LP面临最多的就是无常损失。当场外价格和流动池内对应代币的价格往任何方向偏离时,就会产生这种损失。AMM中的流动池不会自动感应到场外价格,当流动池中代币的价格偏离正常市场价格时,就需要套利者这个角色帮助让价格逐渐回归正常。套利者在资金池内赚取差价,而这个利润就是从LP资金中抽离的,因此会对用户资金造成一定损失。只要AMM中的代币当前价格恢复到LP存入时的原始值,这种损失就会消失,但这种情况很少见。第二, 资本效率低。从恒定乘积做市商的量价模型函数来看,LP提供的流动性均匀分布在价格(0-∞)的曲线上。只有当定价曲线变化区间很大时,流动资金的很大一部分才可以交易流通,这可以称为被动做市。被动做市的缺点是当交易活跃时,当前价格附近的流动性很快会枯竭,同时伴随滑点升高,价格快速发生较大偏离,导致交易停止,这样使得流动性池的资金使用率不高,这是现在大部分DEX的现状。Uniswap3在引入主动做市协议,希望解决这一问题,但似乎并不是很智能。第三, 多代币敞口的风险。作为LP需要购买另一种资产以提供流动性,这将增加对另一资产的敞口,意味着要承受多重代币价格浮动的风险。DeFi的世界是狂野而又充满创作力的,这是一个全新的赛道,创新被赋予了充分的空间。AMM模型的不断创新在推动DeFi的金融获取和去中心化使命中发挥了关键作用。编辑于 2022-02-21 23:16加密货币交易所赞同 2添加评论分享喜欢收藏申请
宸极实验室—『CTF』AMM 算法详解与应用 - 知乎
宸极实验室—『CTF』AMM 算法详解与应用 - 知乎切换模式写文章登录/注册宸极实验室—『CTF』AMM 算法详解与应用九州信泰已认证账号介绍:之前在RSA题目中遇到过的e和phi不互素的问题,可以采用AMM开根算法来解决这个问题,本篇来了解有限域上的AMM开根算法。0x00 前言去年年末的比赛中遇到过多次AMM开根的题目,这类题目特征还是比较明显,所以学习整理记录一下相应的算法与原理。0x01 AMM算法详解1.1 开2次方以开2次方为例我们来看一下AMM开根方法思路。首先对于2次方式子我们有:把上面的p-1的变式代入可得到:对于一个非二次剩余Y:此时如果t=1,那么上式为:此时我们两边同乘x在开根得到:此时代入密文c就可以求出明文:所以明文m就等于:举一个简单的例子:这里的2就是明文,4就是密文。我们继续看⬇️对上式开根,可以得到两种结果:这里的k是为了控制是否引入非二次剩余项,我们开出正根k=0,开出负根k=1,之后不断对x开根,一直到2的指数为0,一共t-1个k:此时,乘二次剩余x然后两边取平方:和上面一样把c带入就可以求出明文了:0x02 例题介绍2.1 题目题目是一个组合题,前面的解密步骤就让我们得到了如下信息:e = 1531793
p = 152103631606164757991388657189704366976433537820099034648874538500153362765519668135545276650144504533686483692163171569868971464706026329525740394016509191077550351496973264159350455849525747355370985161471258126994336297660442739951587911017897809328177973473427538782352524239389465259173507406981248869793
q = 152103631606164757991388657189704366976433537820099034648874538500153362765519668135545276650144504533686483692163171569868971464706026329525740394016509185464641520736454955410019736330026303289754303711165526821866422766844554206047678337249535003432035470125187072461808523973483360158652600992259609986591
n = p * q
c = 23129683905221590810931073733257240695491909600600821626110967741991475952367362466435001712032183901737453265086024660692796844392297498997208235843621067335947024294793917437465567235097523891328309930140339168673282959013006525102332444767839426566939309039615858490944730603509080574471734733118066791730903874584695936232044353090855494398794086718463881637739165577843547326511641921822024263267673375341299485422153934060527418515955523844699687688348603999820720218160844840953001023840468960215702467203343095303314120059019184362079713388502293450806476408625709403546751299379519145557188933345613844133126得到这些信息后,首先我们发现e比较小,按常理有了这些数据应该用常规的rsa解密解出flag了,但是这里你就会发现求d的时候会报错,我们可以发现,e和(p-1)是不互素的,(p-1)正好是e的倍数,此时,就符合了我们AMM算法的第二种情况,可以利用AMM算法求解。2.2 解题思路解题脚本:from Crypto.Util.number import *
import gmpy2
import time
import random
from tqdm import tqdm
e = 1531793
p = 152103631606164757991388657189704366976433537820099034648874538500153362765519668135545276650144504533686483692163171569868971464706026329525740394016509191077550351496973264159350455849525747355370985161471258126994336297660442739951587911017897809328177973473427538782352524239389465259173507406981248869793
q = 152103631606164757991388657189704366976433537820099034648874538500153362765519668135545276650144504533686483692163171569868971464706026329525740394016509185464641520736454955410019736330026303289754303711165526821866422766844554206047678337249535003432035470125187072461808523973483360158652600992259609986591
n = p * q
c = 23129683905221590810931073733257240695491909600600821626110967741991475952367362466435001712032183901737453265086024660692796844392297498997208235843621067335947024294793917437465567235097523891328309930140339168673282959013006525102332444767839426566939309039615858490944730603509080574471734733118066791730903874584695936232044353090855494398794086718463881637739165577843547326511641921822024263267673375341299485422153934060527418515955523844699687688348603999820720218160844840953001023840468960215702467203343095303314120059019184362079713388502293450806476408625709403546751299379519145557188933345613844133126
def AMM(o, r, q):
start = time.time()
g = GF(q)
o = g(o)
p = g(random.randint(1, q))
while p ^ ((q-1) // r) == 1:
p = g(random.randint(1, q))
print('[+] Find p:{}'.format(p))
t = 0
s = q - 1
while s % r == 0:
t += 1
s = s // r
print('[+] Find s:{}, t:{}'.format(s, t))
k = 1
while (k * s + 1) % r != 0:
k += 1
alp = (k * s + 1) // r
print('[+] Find alp:{}'.format(alp))
a = p ^ (r**(t-1) * s)
b = o ^ (r*alp - 1)
c = p ^ s
h = 1
for i in range(1, t):
d = b ^ (r^(t-1-i))
if d == 1:
j = 0
else:
print('[+] Calculating DLP...')
j = - discrete_log(d, a)
print('[+] Finish DLP...')
b = b * (c^r)^j
h = h * c^j
c = c^r
result = o^alp * h
end = time.time()
print("Finished in {} seconds.".format(end - start))
print('Find one solution: {}'.format(result))
return result
def onemod(p,r):
t=p-2
while pow(t,(p-1) // r,p)==1:
t -= 1
return pow(t,(p-1) // r,p)
def solution(p,root,e):
g = onemod(p,e)
may = set()
for i in range(e):
may.add(root * pow(g,i,p)%p)
return may
def union(x1, x2):
a1, m1 = x1
a2, m2 = x2
d = gmpy2.gcd(m1, m2)
assert (a2 - a1) % d == 0
p1,p2 = m1 // d,m2 // d
_,l1,l2 = gmpy2.gcdext(p1,p2)
k = -((a1 - a2) // d) * l1
lcm = gmpy2.lcm(m1,m2)
ans = (a1 + k * m1) % lcm
return ans,lcm
def excrt(ai,mi):
tmp = zip(ai,mi)
return reduce(union, tmp)
cp = c % p
mp = AMM(cp,e,p)
mps = solution(p,mp,e)
for mpp in tqdm(mps):
ai = [int(mpp)]]
mi = [p]
m = CRT_list(ai,mi)
flag = long_to_bytes(m)
if b'flag' in flag:
print(flag)
exit(0)0x03 后记AMM开根算法在密码学中还算最近是比较常见的题型,大家有兴趣可以看一些这方面的文章进一步学习一下。Referencehttps://arxiv.org/pdf/1111.4877.pdfhttps://clingm.github.io/2022/10/02/AMM-Algorithm/https://www.anquanke.com/post/id/262634发布于 2023-04-20 13:30・IP 属地山东CTF(Capture The Flag)赞同 21 条评论分享喜欢收藏申请
你知道最近流行的AMM(自动做市商)是啥不? - 知乎
你知道最近流行的AMM(自动做市商)是啥不? - 知乎首页知乎知学堂发现等你来答切换模式登录/注册音乐做市商你知道最近流行的AMM(自动做市商)是啥不?关注者106被浏览155,045关注问题写回答邀请回答好问题 7添加评论分享15 个回答默认排序拔丝地瓜 关注【一文读懂 DeFi 自动做市商崛起原因、尚存局限和未来前景】以太坊 1.0 的严重限制让简便的 Uniswap 脱颖而出,但以太坊 2.0 和 L2 链下系统将使更复杂的市场蓬勃发展。更全面了解自动化做市商,阅读《链闻精选好文丨读懂 DeFi 热门赛道「自动化做市商 AMM」》想象一下,有个大学时的朋友联络你说:「嘿,我有个商业设想。我想开发一个做市机器人。不管谁来询价,我随时都能报出一个价格,我的定价算法会用 x * y = k。差不多就这些。想投资吗?」你会躲得远远的。其实,你朋友刚才描述的就是 Uniswap。Uniswap 也许是世界上最原始的链上做市商运作。莫名其妙的,它的交易量过去几个月出现爆发式增长,凭交易量已成为世界最大的去中心化交易所(DEX) 。如果你并未密切关注去中心化金融(DeFi) 去年发生的事情,你也许会问,到底发生了什么?Uniswap v2 交易额,数据来源:http://Uniswap.info(如果你已经熟悉 Uniswap 和自动化做市商,即 AMM,请跳过下面章节,直接阅读「AMM 的寒武纪爆发」)给新手们普及一下:Uniswap 是一个自动做市商,即 AMM。你可以把 AMM 设想成一个原始的、机器人式的做市商,它根据一个简单的定价算法,在两种资产之间随时提供报价。对 Uniswap 而言,它对这两种资产进行报价,其持有的每种资产的单位数相乘,总会等于一个常数。这听上去有些拗口:如果 Uniswap 拥有一些 x 代币,拥有一些 y 代币,它给每一笔交易定价,所以,它拥有的 x 的最终数量,和拥有的 y 的最终数量,两者相乘会等于一个常数 k。这就形成了一个常数积的等式:x * y = k。这种对两种资产进行定价的方式,你可能会觉得非常怪异且过于独断。让两种代币的库存数相乘所得的积维持固定,为什么就能确保正确的报价呢?Uniswap 示例假设我们在 Uniswap 的某个池里投入 50 个苹果 (a) 和 50 个香蕉 (b) ,任何人都可以用苹果换香蕉,或者用香蕉换苹果。假设一级市场中苹果与香蕉的汇率刚好是 1:1。因为该 Uniswap 资金池中分别有 50 个苹果和 50 个香蕉,因此,按上述常数积的等式规则,a * b = 2500 。对于任何交易,Uniswap 都需要保证,池中库存的苹果数和香蕉数相乘等于 2500。好了,假设一位客户进入我们的 Uniswap 池来买一个苹果。她应该支付多少个香蕉呢?如果她买走一个苹果,我们的池里就剩下 49 个苹果,而 49* b 依然需要等于 2500。这样香蕉的总数 b 就等于 51.02。由于之前池中有 50 个香蕉,因此我们还需要 1.02 个香蕉(在这个宇宙中我们允许碎片化香蕉的存在) ,因此,这位客户买一个苹果会得到的报价是:1.02 香蕉 / 苹果。请注意,这与两者之间 1:1 的原始价格很接近!因为这只是一笔小额交易,所以滑点较小。但如果订单很大呢?你可以将这条曲线每个点的斜率解读为边际交换率如果她想买 10 个苹果, Uniswap 的报价会是 12.5 个香蕉,即这 10 个苹果每个的单价为 1.25 香蕉 / 苹果。如果她想要执行 25 个苹果这种大额交易,即要买库存苹果数量的一半,那么,单位价格会上涨到 2 香蕉 / 苹果! (你能从直觉上明白这一点,因为池中的一种商品减半,另一种就得翻倍)重要的是需要明白,Uniswap 不能偏离这条定价曲线。如果某人要购买一些苹果,后来又有人要买一些香蕉, Uniswap 就会在这条价格曲线上来回移动,无论需求把它带向何方。Uniswap 在一系列交易后,在定价曲线上来回移动这里有个好玩的地方:如果苹果与香蕉之间的真实交易价格是 1:1,当第一位客户买走 10 个苹果后,我们 Uniswap 池就有会变成 40 个苹果和 62.5 个香蕉。如果有位套利者此时进入,她买走 12.5 个香蕉,让资金池恢复到最初状态,她只需付 10 个苹果,所以 Uniswap 对她的收费只有 0.8 苹果 / 香蕉。Uniswap 会低价甩卖香蕉!就好像我们的算法此时意识到香蕉过多,所以它低价抛售香蕉,以吸引苹果流入,从而实现库存的再平衡。Uniswap 经常跳这种舞步——稍微偏离真实的交易价格,然后在套利者的帮助下缓步回归正常。套利损失(Impermanent Loss)简介下面你将了解 Uniswap 定价机制的工作方式。但这仍然引出一个问题——Uniswap 很好的完成了它工作吗?这东西真的会产生利润吗?毕竟,任何做市商都可以报价,但是否赚钱就不好说了。答案是:取决于具体情况!具体来说,这取决于一种被称为「套利 损失」(Impermanent Loss) 的概念。它的运作方式如下:Uniswap 会对每笔交易收取少量费用 (目前为 0.3%) 。这是在名义价格之外的。因此,如果苹果和香蕉总是且永远以 1:1 价格进行交易,随着做市商在交易价格曲线上来回移动,这些费用将随时间累积。那么,与只持有 50 个苹果和 50 个香蕉的基线比较,Uniswap 池最终会积累更多的水果。但是,如果苹果和香蕉之间的真实交易价格突然发生变化,会发生什么呢?假设某家香蕉农场遭遇了无人机攻击,出现大面积的香蕉短缺。香蕉现在像黄金一样贵。交易价格蹿升到 5 个苹果换 1 个香蕉。Uniswap 上会发生什么?套利者一秒都不会耽搁,立马杀入你的 Uniswap 池,抢购便宜的香蕉。他们调整交易规模,以便买走价格低于新汇率 5:1 的所有香蕉。这意味着他们需要移动价格曲线,直到满足以下等式:5x * x = 2500。算一下这个数学题,你会得到如下结果:他们总共以 61.80 个苹果买到 27.64 个香蕉。平均交易价格为 2.2 个苹果:1 个香蕉,这远低于市场价,相当于得到 76.4 个免费苹果。他们的利润从何而来?当然这是以牺牲资金池为代价的!而且,如果数一下你会发现,与某个持有最初的 50 个苹果和 50 个香蕉的人相比,Uniswap 池现在恰好下降了 76.4 个苹果的价值。Uniswap 出售香蕉的价格太便宜,因为它不知道香蕉在现实世界中变得如此值钱。这种现象称为「套利 损失」。每当交易价格发生变动,就会出现套利者窃取廉价资产,直到资金池的定价达到正确为止。 (这些损失是「暂时的」,因为如果后来真实交易价格恢复为 1:1,那么就好像你从未损失过这笔钱,和开始相比。)资金池通过交易费赚钱,通过套利损失而亏钱。这都是需求和价格背离的一个函数——需求有利于资金池,而价格背离不利于资金池。这就是 Uniswap 的简单概括。当然你可以更深入地了解,不过,要了解该领域内的情况,上面的知识也足够了。自 2018 年上线以来, Uniswap 已经席卷 DeFi 领域。考虑到 Uniswap 的原始版本只有大约 300 行代码,这一成绩尤其令人惊讶! (AMM 本身拥有历史悠久的血统,但是常数函数做市商是一个相对较新的发明。) Uniswap 完全无需许可,任何人都可以注入资产。它甚至不需要预言机。回顾一下会发现它非常优雅,是可能发明的最简单的产品之一,它似乎从石头缝里诞生,并主导了 DeFi 领域。AMM 的寒武纪爆发自从 Uniswap 崛起之后,AMM 的创新也迎来了爆发。Uniswap 的后继者纷纷涌现,每个都有其特殊功能。Uniswap、 Balancer 和 Curve 的交易额,来源:Dune Analytics尽管它们都继承了 Uniswap 的核心设计,但各自具有自己的特殊的定价函数。例如,Curve 使用常数乘积和常数和的混合模式,Balancer 的多资产定价函数用一个多维平面来定义。甚至有些采用移动的曲线,这可以耗尽库存,例如 Foundation 用于销售限量版商品的曲线就是如此。Curve 中采用的 Stableswap 曲线 (蓝色),来源:Curve 白皮书不同的曲线适用于特定的资产,因为它们对所报价资产之间的价格关系置入了不同的假定。从上图可以看到,Stableswap 曲线 (蓝色) 在多数情况下接近于一条直线,这意味着在其大部分交易区间,两种稳定币的定价相互非常接近。常数积(constant product) 曲线是任何两种随机资产不错的起点,但是如果我们知道这两个资产是稳定币,并且它们的价值可能大致相同,那么 Stableswap 曲线会给出更具竞争力的定价。当然,一个 AMM 可以选择无限多种特定曲线来定价。我们可以对所有这些不同的定价函数进行抽象化,将整个类别称为恒定函数做市商(CFMM) 。当看到 CFMM 交易额的增长,人们想当然的认为,它们将接管世界——将来所有链上流动性将由 CFMM 提供。但变化没有那么快!CFMM 如今占主导地位。不过,为了更清楚地了解 DeFi 的进化情况,我们需要了解 CFMM 何时繁荣,以及何时表现不佳。相关性的频谱还是以 Uniswap 为例,因为它是最容易分析的 CFMM。假设你想成为 Uniswap 上 ETH / DAI 池的流动性提供商(LP) 。在向该池提供资金时,你必须同时相信以下两点,才会认定,成为一个 LP 比仅持有原始资产要好得多:ETH 与 DAI 的价值比不会发生太大变化 (如果发生变化,将表现为套利损失)这个池会收到很多交易费就该资金池展现的套利损失而言,获得的交易费应该超过损失。请注意,对于包含稳定币的交易对,你对 ETH 上涨有多么看多,你其实也在假设会有很多的套利损失!一般性的原则是:当两种资产是均值回归时,Uniswap 理论运作得最好。想象有一个 USDC/DAI 或 WBTC/TBTC 的资产池——这些池应该会显示出极小的套利损失,随时间推移将纯粹累积交易费。请注意,套利损失不只是一个波动性问题(实际上,波动性极高的、均值回归的交易对是很不错的,因为它们会产生大量的交易费)因此,我们可以绘制出利润最高的 Uniswap 资金池的层级图,其他条件保持一致。均值回归交易对的情况很明显。相互关联的交易对,其价格往往一起移动,因此 Uniswap 不会有太多套利损失。而像 ETH/DAI 这样不相关的交易对,情况就不太确定,有时候交易费可以弥补损失。最右边是逆相关的交易对,Uniswap 上这种资金池就很糟糕了。想象一下,有人在某个预测市场做多特朗普,做多拜登,并将两笔押注放入 Uniswap 的一个资金池。从定义上说,最终将有一笔资产值 1 美元,另一笔资产则为 0。该资金池的结果是,某个 LP 一无所获,只有套利损失! (预测市场总是在市场结清之前停止交易,但结果往往早在市场真正结清之前已经水落石出。)所以 ,Uniswap 对某些交易对运转良好,而对另一些交易对而言就是灾难。但是人们很容易发现,到目前为止,几乎所有头部 Uniswap 资金池都是赚钱的!实际上,甚至 ETH / DAI 资金池自创建以来也是赚钱的。Uniswap 上 ETH/DAI 资金池的回报(vs 持有 50/50 的 ETH/DAI),来源:ZumZoom Analytics这个现象需要解释。尽管存在瑕疵,各 CFMM 都是取得了不俗收益的做市商。这怎么可能呢?要回答这个问题,需要了解一下做市商的工作机制。做市机制简介做市商的工作是向某个市场提供流动性。做市商主要通过三种方式赚钱:指定做市安排(传统上由资产发行商支付费用) 、交易费回扣 (传统上由交易所支付) 以及从做市中赚价差(Uniswap 正是这种方式) 。你可以看到,所有的做市都是与两种订单流进行一场战斗:知情订单流和不知情订单流。假设你为 BTC/USD 市场报价,有一笔大额 BTC 卖单到了。你得问问自己:这是有人在换取流动性,还是这人知道一些我不清楚的消息?如果这名交易对手知道庞氏骗局(PlusToken) 的缓存池发生了变动,卖压正在来袭,那么,你就只能用一些完美无缺的 USD 换一些前景不太妙的 BTC。另一方面,如果这只是某些无名人士在卖币,因为他们需要支付房租,那么,这就没什么特别的意义,你从他们身上赚价差就好了。作为一名做市商,你从不知情交易流中赚钱。不知情交易流是随机的——每天有人卖有人买,最终会相互抵消。如果对每笔交易赚价差,长期来说你会赚钱。 (这解释了为什么做市商们会花钱获得来自 Robinhood 交易所的订单流,因为后者多数是不知情的散户订单) 。所以,一名做市商的首要任务是区分知情和不知情订单流。某个流是不知情的流的可能性越大,你收取的价差就该越高。如果这个订单流绝对是知情的,那你就应该完全撤回报价单,因为若是知情的交易方愿意与你交易,你绝对是要亏钱的。(考虑这一问题还有一种思路:不知情的订单流愿意为一种资产支付高于市价的价格, 这就是你赚的价差。而知情订单流只愿意以低于市价获取某种资产,所以,每当你与他们交易,你实际是在价格上吃亏的一方。这些订单知道你不知道的一些信息。)同样的原则也适用于 Uniswap。有些人在 Uniswap 交易,因为他们完全是随机的想用 ETH 换 DAI 。对做市商而言,这是不知情的散户流,随机漫步的交易活动会带来费用收入。这很爽。你面对的还有套利者:他们是知情订单流。他们在选择价格错误的资金池。某种程度上说,他们其实是在帮助 Uniswap 将交易价格拉回正轨。但另一方面,他们是把 LP 的钱转移到他们自己的兜里。做市商若要想赚钱,他们需要让不知情散户流与套利流之比做到最大。但 Uniswap 无法区分这两种流!Uniswap 不清楚一笔订单是来自懵懂无知的散户,还是某个套利者。无论市场条件是什么情况,它只遵循 x * y = k 的方程。因此,只要有一个新玩家提供比 Uniswap 更好的定价,比如 Curve 或 Balancer,那么,你会看到散户订单流迁移到定价更好的服务去。鉴于 Uniswap 的定价模型和固定费率(每笔交易收 0.3%) ,你很难看到它能在竞争最激烈的资金池中竞争 —— Curve 既对稳定币交易进行了优化,而且每笔交易的收费仅为 0.04%。随着时间的推移,如果 Uniswap 资金池在滑点上被对手超越,那么,留在 Uniswap 的大多数将会是套利订单流。零售流是多变的,但随着市场变动,套利机会持续出现。这种定价方面丧失竞争力不仅很糟,其弊端还被放大了。Uniswap 在发展上升期对流动性有网络效应, 但在下坡时期也被严重放大。当 Curve 开始吃掉稳定币相关的交易额时,Uniswap 上的 DAI/USDC 交易对将开始丢失 LP,这反过来让定价更糟,吸引的交易额也会更少,再进一步抑制 LP,恶性循环。网络效应也是如此——在上升期就像是火箭, 但在下降时则烧毁了归路。当然,这种说法同样适用于 Balancer 和 Curve。一旦被一个定价更好、费用更低的做市商超越,他们也很难维持其费用收入。不可避免的,这一切的结果就是一种费用的向下竞争,和利润空间的大幅压缩。 (传统市场的做市商领域上演的就是同样剧目!这是一门竞争超级激烈的生意!)但这仍然不能解释:为什么所有的 CFMM 都在疯长?为什么 CFMM 高歌猛进?以稳定币为例。CFMM 明显正在夺取这一垂直领域。想象一下,传统金融市场中的某个重量级做市商(比如 Jump Trading) 准备在 DeFi 领域开始进行稳定币的做市。首先他们前期需要大量的整合工作, 然后,为了持续运营,他们需要向交易者持续付费、维护交易软件、支付办公室租金。他们需要大量的固定成本和运营成本。而 Curve 根本不需要成本。一旦智能合约部署完毕,它就自行运营(连计算成本、gas 费用完全都由终端用户来支付!)如果为 USDC/USDT 交易对报价,Jump Trading 要做的事情会比 Curve 的做法复杂很多。稳定币做市相当程度上是库存管理。这里没有那么多花哨的机器学习 (ML ) 或专有知识,如果 Curve 能做到 Jump 水准的 80%, 那就算足够好了。但 ETH/DAI 是一个复杂得多的市场。当 Uniswap 报价时, 它不像 Jump 那样,要看交易所订单簿,要流动性建模或参阅历史波动性,它只是闭上眼睛,大喊 x * y = k !与普通的做市商相比,Uniswap 的复杂度相当于一台冰箱。但只要正常的做市商没有进入 DeFi 领域,Uniswap 就会垄断该市场,因为它的启动成本和运营成本为零。这是另一种思考的方式:Uniswap 是第一个在这个名为 DeFi 的新市场开店的小商贩。即使有种种缺陷,Uniswap 也形成了一种虚拟的垄断。当你有垄断地位,你就得到所有的散户订单流。散户流和套利流之比,是决定 Uniswap 盈利情况的主要因素, 难怪 Uniswap 正在赚大钱!但是,一旦散户流开始转向别处,这一良性循环很可能寿终正寝。LP 将开始遭受损失并撤出流动性。但这只是解释了一半。要记住:在 Uniswap 出现之前, 已经存在大量的去中心化交易所 (DEX) !Uniswap 摧毁了基于订单簿的 DEX, 比如 Idex 或 0x 。到底是什么因素让 Uniswap 击败了所有的订单簿模式交易所呢?从订单簿到 AMM我相信,Uniswap 之所以击败订单簿交易所,有四个原因。首先,Uniswap 的实施极其简单。这意味着复杂性低、遭遇黑客攻击的表面积低、集成成本低。更何况,它有很低的 gas 成本!当你在一个相当于去中心化的图形计算器上执行所有交易时,这一点真的很重要。这不是一个小问题。一旦新一代高吞吐量的区块链成为现实,我怀疑订单簿模式是否最终还能居于主导地位,就像它在常规金融世界中那样。但它会在以太坊 1.0 上占据主导地位吗?以太坊 1.0 的严重限制让简便性脱颖而出。当你不能做复杂的事情时,你必须做最好的简单的事情。Uniswap 是一个相当不错的简单产品。其次,Uniswap 的监管面非常小(这也是文件共享程序 Bittorrent 发明者 Bram Cohen 认为 Bittorrent 会成功的原因) 。Uniswap 是非常去中心化的,不需要链下输入。订单簿 DEX 必须像经营一家交易所一样亦步亦趋,与此不同,Uniswap 可以作为一种纯粹的金融应用而自由创新。第三,向 Uniswap 提供流动性非常容易。一键式「设置,然后忘记」的操作,让 LP 的体验无比轻松 (活跃的做市商在某个订单簿交易所提供流动性的操作要麻烦得多) ,尤其是在 DeFi 交易量放大之前。这一点至关重要,因为 Uniswap 上的大量流动性是由一小群好心的巨鲸提供的。这些巨鲸对投资回报没有那么敏感,所以 Uniswap 的一键式体验使得他们能够毫无痛苦地参与其中。加密项目设计者有一个忽视心理交易成本的坏习惯,且总是假定市场参与者无比勤奋。Uniswap 使流动性供应变得简单,这一点得到了回报。Uniswap 之所以如此成功的最后一个原因是,创建带激励的资金池非常方便。在一个带激励的资金池中,资金池的创建者将代币空投给 LP,使 LP 得到的回报高于 Uniswap 标准回报。这种现象也被称为「流动性农场」 (liquidity farming) 。Uniswap 中一些规模最大的资金池通过空投进行激励,包括 AMPL、sETH 和 JRT。对于 Balancer 和 Curve,它们的所有资金池当前都使用自己的原生代币进行激励。回想一下,传统做市商赚钱有三种方式,其中一种是指定的做市协议,由资产发行人付款。从某种意义上说,带激励的资金池是 DeFi 领域的指定做市商协议:某资产的发行者向 AMM 付费,让后者为他们的代币交易对提供流动性,而费用则通过代币空投来交付。但是,带激励的资金池还有另外一个维度。CFMM 不仅仅是扮演做市商,它们现在具备代币项目的营销和分销工具的双重身份。通过带激励的资金池,CFMM 创建了一种防女巫攻击的方式,将代币分发给想要累积代币的投机者,同时引导了一个流动的初始市场。它还让购买者手里的代币有其他用处——不只是转手把它卖掉,存起来还能得到一些收益!你可以称之为乞丐版质押。对早期代币项目而言,这是一个强大的营销武器,我期望这一点被整合到代币上市的行动手册中。这些因素深度解释了为什么 Uniswap 如此成功的原因 (我还没有谈到「首次 DeFi 发行」Initial DeFi Offerings,这是改天再讨论的话题) 。话虽如此, 我不相信 Uniswap 的成功会永远持续下去。如果说以太坊 1.0 的局限为 CFMM 形成主导地位创造了条件,那么以太坊 2.0 和 L2 链下系统将使更复杂的市场蓬勃发展。此外,DeFi 的明星项目在不断涌现,随着大量用户和交易额的到来,它们将吸引严肃的传统做市商。随着时间的推移,我预计这会导致 Uniswap 的市场份额缩水。再过五年, CFMM 会在 DeFi 中扮演什么角色?我预期,到 2025 年时,CFMM 今天这样的面貌不会成为人们交易的主要方式。在技术史上,这样的过渡很常见。在互联网的早期,像雅虎这样的门户网站是第一批在网上大幅领跑的企业。早期网络环境的局限性 (如速度慢等) ,非常适合由人工制作的页面目录。随着主流用户开始上线,这些门户网站取得了疯狂的增长!但是我们现在知道,门户网站只是组织互联网信息道路上的临时垫脚石。最初的雅虎网站主页和最初的谷歌网站主页CFMM 是什么未来事物的垫脚石?会有新生事物取代它,还是 CFMM 随着 DeFi 一同演变?我会在下一篇文章中尝试回答这个问题。详见:发布于 2020-07-23 15:09赞同 29515 条评论分享收藏喜欢收起匿名用户作者:Chainlink,翻译:凌杰基于自动做市商(AMM)的去中心化交易所(DEX)已被证明是最具影响力的DeFi创新之一。它们可以为一系列不同的代币创建和运行可访问的链上流动性。AMM从根本上改变了用户交易加密货币的方式。交易的双方都没有使用传统的买卖订单簿,而是由链上流动性池预先提供资金。流动性池允许用户以完全去中心化和非托管的方式在链上进行无缝的代币兑换。根据流动性提供者对资金池的贡献百分比,他们可以通过获得相应的交易费收入。在本文中,我们将探究AMM的工作原理,分析其固有问题,并研究解决这些关键障碍的方案。关键点包括:几种AMM类型:恒定总和做市商(CSMM)、恒定平均值做市商(CMMM)和混合常数函数做市商(CFMM)。AMM必须克服的一些关键挑战,包括:暂时性亏损、多代币敞口( forced multi-token exposure)和低资本效率。Bancor、Uniswap、Curve等公司通过提高资本效率、降低波动风险和提供更多的资本配置选项,使AMM对大型流动性提供者更具吸引力。通过使用Chainlink oracles,Bancor的目标是在他们即将发布的V2版本中率先解决波动性代币的暂时性亏损问题。通过提供更详尽的分析,我们希望能让DeFi用户更好地了解AMM的面临的挑战和创新,以便去中心化的流动性能够充分发挥其潜力,成为DeFi和更广泛的金融世界的基础基石。自动做市商(AMM)概述做市商(MM)是负责在交易所提供价格的实体,否则没有交易活动就会缺乏流动性。做市商从自己的账户买入和卖出资产,最终目的是为了获利。他们的交易活动为其他交易者创造了流动性,降低了交易的滑点。自动做市商(AMM)使用算法 "Money Robots "来模拟DeFi等市场内的价格行为。虽然不同的去中心化交易所设计不同,但基于AMM的DEX一直以来都拥有最大的流动性和最高的日均交易量。恒定函数做市商(CFMM) 是最受欢迎的一类AMM,专门为实现数字资产的去中心化交易而设计的。这些AMM交易所基于恒定函数,交易对的综合资产储备必须保持不变。在非托管式AMM中,各个交易对的用户保证金被集中在一个智能合约内,任何交易者都可以利用该合约进行代币兑换。因此,用户是与智能合约(集合资产)进行交易,而不是像在订单簿交易所那样直接与对手方进行交易。自2017年以来出现了三种恒定函数做市商。出现的第一种类型是 恒定乘积做市商(CPMM) ,并在首批基于AMM的DEX,Bancor和Uniswap中得到得到推广。CPMM基于函数x*y=k,该函数根据每个代币的可用数量(流动性)确定了两个代币的价格范围。当X的供应量增加时,Y的供应量必须减少,反之亦然,以保持k的乘积不变。当绘制出曲线,结果是一个双曲线,其中流动性总是可用的,但当价格越来越高,两端将接近无穷。(source:Dmitriy Berenzon )第二种类型是 “恒定总和做市商”(CSMM) ,它非常适合零滑点交易,但不能提供无限的流动性。CSMM遵循公式x + y = k,在绘制时会创建一条直线。不幸的是,如果代币之间的链下参考价格不是1:1,则这种设计允许套利者耗尽其中的一项储备。这种情况将破坏流动资金池的一侧,迫使流动资金提供者承担损失,而交易者则没有更多的流动资金。因此,CSMM是AMM的罕见模型。(source:Dmitriy Berenzon )第三种是 恒定平均值做市商(CMMM) ,它可以创建具有两个以上代币的AMM,并在标准的50/50分布之外进行加权。在这个模型中,每个代币储备的加权几何平均值保持不变。对于一个有三种资产的流动性池,公式如下。(x*y*z)^(⅓)=k。这就允许池内不同资产的风险敞口可变,并可在池内任何资产之间进行互换。随着基于AMM的流动性的发展,我们看到了先进的混合常数函数做市商(CFMM)的出现,这些混合型常数函数做市商结合了多种功能和参数,以实现特定的行为,如调整流动性提供者的风险敞口或减少交易者的价格滑点。例如,Curve的AMM结合了CPMM和CSMM,以创造更好的流动性,在给定的交易范围内降低滑点。其结果是一个双曲线(蓝线),对大多数交易返回线性汇率,而对大额的交易只返回指数价格。(source:Curve Whitepaper)本文其余部分将主要关注不同的AMM设计,这些设计旨在解决AMM的关键挑战。虽然DeFi中的第一代AMM池在过去两年中经历了爆发式增长,但仍然有一些障碍阻止它们的广泛采用,包括暂时性亏损、低资本效率和多代币敞口等问题。阻碍AMM的 内在 问题暂时性 亏 损 ( Impermanent Loss )用户向AMM池提供流动性的主要风险(也是最不为人所知的风险)是暂时性亏损——在AMM中存入代币与仅仅在钱包中持有这些代币之间的价值差异。当AMM内的代币的市场价格在任何方向上发生偏离时,就会产生这种损失。由于AMM不会自动调整汇率,因此套利者需要买入价格偏低的资产或卖出价格偏高的资产,直到AMM提供的价格与外部市场的市场价格相匹配。套利者获取的利润是从流动性提供者的口袋里抽走的,这将对流动性提供者造成损失。在上面的示例中,由于可能会因为其他交易所的交易活动,或者ETH的市场价格发生变化,导致AMM内的暂时性亏损。AMM对这种外部价格变化的内部反应是重新调整池中的汇率以匹配外部市场的汇率。在将ETH换成BNT的重新平衡过程中,AMM的总储备金略有下降。之所以称之为 "暂时性 "亏损,是因为只要AMM内的代币相对价格恢复到原来的价值,亏损就会消失,流动性提供者就会把赚取的费用作为利润保留下来。然而,这样的情况很少,这意味着大多数流动性提供者遭受的暂时性亏损超过了他们所收获的交易费用。下图显示了在考虑交易费用之前,为ETH-DAI AMM池提供流动性时经历的暂时性亏损。多代币敞口AMM通常要求流动性提供者存入两种不同的代币,以便为交易双方提供同等的流动性。因此,流动性提供者无法保持对单一代币的长期风险敞口,而不得不通过持有额外的ERC20储备资产来增加其风险敞口。拥有大量一种代币的团队或希望提供流动性的个人将被迫购买另一资产,以提供流动性,从而减少他们在资产池基础代币中的持有量,并增加对另一资产的敞口。低资本效率AMM被批评需要大量的流动资金才能达到与基于订单簿的交易所相同的滑点水平。这是由于AMM流动性的很大一部分只有在定价曲线开始转为指数时才能使用。因此,由于具有较大的滑点,大多数流动性永远不会被理性交易者使用。AMM流动性提供者无法控制提供给交易者的价格,这导致一些人将AMM称为 "懒惰的流动性",其利用率不高且配置不足。同时,订单簿交易所的做市商可以精确控制他们想要购买和出售代币的价格点位。这带来了非常高的资本效率,但同时也带来了需要积极参与和监督流动性供给的代价。改善AMM 的方案第一代AMM的许多局限性已通过具有新设计模式的创新项目得以解决。高资本效率和低滑点的AMM如上一节所述,混合CFMM 仅在流动性池被推到极限时才能够通过汇率曲线(极具线性和抛物线)实现极低的滑点交易。流动性提供者赚取了更多的费用(尽管每笔交易的费用较低),因为资金的使用效率更高,套利者仍然可以从资金池的再平衡中获利。Curve提供代币之间的低滑点交换,这些代币具有相对稳定的1:1汇率。这意味着它的解决方案主要是为稳定币设计的,尽管他们最近推出了对可以稳定交易的代币对的支持,如打包版本的比特币(renBTC和wBTC)。Bancor V2通过类似的机制将这种低滑点模型扩展到波动性资产,该机制可动态更新池的储备权重,以将储备价值保持为1:1的比率。可以在共同的价格区域内扩大流动性,同时保留了对套利者重新平衡资金池的激励。减轻暂时性 亏 损Bancor的目标是在即将发布的V2版本中率先解决波动性代币的暂时性亏损问题。Bancor V2通过使用挂钩的流动性储备,保持其AMM储备的相对价值不变,从而减轻了短暂性损失的风险。直到最近,这完全是通过保持恒定的1:1价格比率的镜像资产对来实现的。但Bancor V2使用Chainlink oracles将这一概念扩展到具有可变汇率的资产。这样的解决方案将是AMM中利用非稳定币数字资产的重大突破,因为流动性提供者的风险降低了。通过使用Chainlink oracle,Bancor V2池能够保持准确的汇率,即使代币的定价因外部市场价格变化而出现分歧。oracle不是由套利者固定汇率,而是提供价格更新,调整AMM的权重,使内部汇率与外部市场价格相匹配。这样做的好处是,套利者不再以暂时性亏损的形式从流动性提供者那里抽走价值。相反,套利者只需要在AMM池中平衡代币分布,以应对代币交易。Bancor V2始终鼓励恢复平衡,因为权重较低的储备的流动性提供者赚取更高的投资回报率,直到AMM池回归到50/50权重。总的来说,用户和代币团队都可以对他们存入的流动性产生交易费用的利润更有信心,并且不会因为常规的市场变动而失去价值。多代币敞口Uniswap V2允许任何ERC20代币与任何其他ERC20代币合并,消除了流动性提供者暴露于ETH的要求。这让流动性提供者可以灵活地保持更多样化的ERC20代币头寸组合,并为交易创造更多潜在的流动性池组合,以便从中提取流动性。Bancor V2通过使流动性提供者能够保持对单一代币的风险敞口,消除了双面流动性存款要求。通过Chainlink oracles挂钩流动性储备,用户可以在AMM中保持对任何代币的风险敞口,范围从对任何ERC20代币的100%风险敞口,对BNT的100%风险敞口,或两者之间的任意分布。对于希望完全拥有其首选资产敞口的加密货币投资者而言,这是理想的选择,尤其是在减轻暂时性亏损的同时。这可能会吸引想要在AMM上提供低风险流动性而无需购买额外准备金的代币团队和投资基金。AMM创新与未来从Bancor到Uniswap再到Curve等等,AMM技术正在为任何数字资产获取即时流动性提供新的可能性。AMM不仅在以前缺乏流动性的市场中创造了价格,而且是以一种高度安全、可访问和非托管的方式进行的。虽然AMM已经经历了爆发式增长,但围绕着更高的资本效率、多资产池和减轻暂时性亏损的创新,为吸引来自传统市场的更大的流动性提供者创造了必要的基础。发布于 2020-07-13 11:53赞同 242 条评论分享收藏喜欢
DEX的创新之路|AMM自动做市商科普 - 知乎
DEX的创新之路|AMM自动做市商科普 - 知乎首发于先知实验室切换模式写文章登录/注册DEX的创新之路|AMM自动做市商科普先知实验室作者:JacksonAMM(做市商)贯穿着DeFi世界的始终,同时AMM模型也构建了DeFi世界繁荣的基础。想要构建一个对于DeFi世界的基础认知,建议仔细阅读以下内容,Let's for fun. 什么是AMM(自动做市商)在了解AMM之前,先让我们看看传统意义上的做市商是什么?所谓做市商(AMM),是负责为交易所提供流动性,同时进行价格操作的实体。这是通过MM从自己的账户买卖资产来实现的,他们的目的是为了盈利,他们的交易活动为其它交易者创造了流动性,这降低了大宗交易的滑点,在计算机交易大规模普及之前,做市商是交易市场不可或缺的一部分。加密货币市场同样有着提供流动性和定价的需求,但是在追求去中心化的加密货币市场中,这种中心化的做市商机制并不被人们所使用。于是自动化做市商(AMM)产生,这种机制使用算法“机器人”在DeFi等电子市场中模拟这些价格行为。我们可以把AMM设想成一个原始的,机器人式的做市商,他根据自定的定价模型,在两种资产之间随时提供报价以供用户进行交易。1、AMM类别和其定价模型恒定函数做市商(CFMM)是当前最流行的AMM。当交易者希望在AB代币之间进行交易时,这种AMM会使用恒定函数作为其定价机制。“恒定函数”在此处指的是两种或多种交易资产的储备的某种函数值必须在发生任何交易时保持不变。目前主流的CFMM有以下几种:A .恒定乘积(Uniswap)这种AMM强制要求两种资产储备量的乘积始终保持不变,即:x * y = k在这个等式中,X 和 Y代表流动性池中两种资产的单位数量。举例说明,假设ETH/DAI池包含100ETH(X)和10000DAI(Y)。此时K=1,000,000 。现在的目标是保持k值恒定,而不考虑对流动性池的交易量。做到这一点的唯一方法是,x和y的数量反向变化。换句话说,当x的数量增加时(交易者将ETH加入池中),y的数量必须减少(交易者将DAI从池中取出)。最终,任何给定交易所的报价都是常量乘积公式和池中代币比例的函数。下图近似描述了这种模式下两类资产之间互相兑换的关系。可以看到在这种方式下,两类资产之间的兑换并不成线性关系,而是一个双曲线,这在这种模式下,流动性总是可用的,但是缺点也显而易见:在交易中会产生滑点,尤其是当进行越大宗的交易时,滑点越大。资产的价格有可能会越来越高,两端接近无穷大无法满足挂单交易的需求B .恒定和 (CSMM)这类AMM遵循 x + y = k 的公式,从而在交易中可以实现零滑点。但他的致命之处在于它无法提供无限的流动性,如果作为储备代币的参考价格不等于1,所有套利者会不断买入其中一种代币,直至其流动性耗尽。因此并不是一种常见的AMM机制。C .恒定平均值 (Balancer)恒定平均值做市商由恒定乘积做市商这一概念推广而来,可用于两种以上资产,权重比例不仅限于 50/50 。这一类型实际上是恒定乘积模型的变种,公式如下,其中Bt为资产t的数量,Wt为权重类似于Uniswap,目标是在保持资产权重不变的情况下,只改变资产余额,从而保持k不变。在3种资产Balancer Pool的情况下,交易可以发生在三个资产中的任意两个之间。用户可以用ETH交换DAI,用ETH交换BTC,或者用DAI交换ETH。通过保持k的值不变,可以在三种资产之间生成一个价值面。这个价值实际上与Uniswap的曲线没有太大区别,只不过多了几个维度而已。不同的是,在这种模式下,定价模型变得更加复杂了起来Balancer资金池中可以允许有2-8种资产。池中的每一对代币都有一个价格,这个价格取决于该特定代币的余额B和权重W。从形式上看,交易执行的价格是按照代币余额与代币权重的比值来计算的。在上面的公式中,代币A代表被卖出的代币(进入池子) 而代币B是被买入的代币(离开池子)。如果池子的持有者不改变资产储备,很容易看出价格的变化完全基于交易,因为资产权重必须始终保持不变。这种机制与图2所示的恒定面相结合,可以保证买入资产的价格上升,而卖出资产的价格下降。在与Uniswap相同的情况下,套利机会保证了Balancer Pools提供的价格与市场其他部分同步变动。D . 混合型CFMM (Curve)经过分析以上三种模型我们可以看出,他们都有各自的优缺点,于是一些项目想通过使用混合函数基于资产特性获得理想属性,这其中的代表项目就是CurveCurve是一个交易所流动性池,预期价格稳定的资产之间可以在该池里进行高效交易(如稳定币或封装的比特币(wrapped bitcoin))。Uniswap和Balancer主要是针对波动和价格不稳定的代币的交易。然而,当处理那些想要互相保持稳定的资产之间的交易时,低价格滑点是最重要的。之前迭代的各种AMMs固有曲率就有问题了,因为交易规模越大,滑点就越大。从上面我们看到恒和机制可以达到无滑点,但是它无法做到激励流动性,因此Curve在CSMM的基础之上结合恒定乘积函数创造了一种混合AMM:这个函数在恒定乘积曲线的平衡点附近创建一条相对平坦的曲线,类似于恒定总和函数,以保持价格相对稳定,同时使两端更加倾斜,类似于恒定乘积函数,因此在曲线的每个点都有流动性。在双资产的情况下(x和y),最终的结果是下面的复杂函数。其中n为资产数量(在双资产情况下n=2),A为“放大系数”参数,他决定了函数于恒积函数的相似程度,A值越小,越类似Uniswap的恒积函数,我们无需理解这个函数的构成,只要知道函数的目的还是在交易过程中保持常数K不变。绘制该函数如下:可以看到在函数终端其更类似一条直线,表现为恒和函数,但随着x,y的增大,则向恒积函数靠拢,这种形状使曲线中间段的价格保持稳定,同时又能在两端提供流动性。2、做市模型及潜在风险做市模型:CFMM主要有以下三类参与者:交易者:希望在CFMM中将某类资产交换为另一种资产流动性提供者:提供资产组合(交易对)来满足交易需求,赚取交易费套利者:通过套利行为将交易对中的资产维持在市场价格在这三类参与方中,最重要的角色是流动性提供者(LP),负责向 DEX 的智能合约中注入自己的资产,作为资产储备池,为交易提供流动性,并以此获取交易费用收益。其次是套利者,他们负责修正交易价格,保证交易价格与市场价格一致,但也会产生无常损失(Impermanent Loss),给流动性提供者带来亏损的风险。我们以 Uniswap 中资产 A 和资产 B 的交易为例。在交易开始前,我们需要向区块链的智能合约中注入 x 数量的资产 A 和 y 数量的资产 B 来作为流动性储备,即在公式 x*y=k 中, x,y 和 k 的初始值由流动性提供者(LP)确定。因为资产 A 和资产 B 之间的初始价格 P = x / y,所以当第一个流动性提供者(LP)把自己认为等价值的资产 A 和资产 B 充值到此智能合约中,就可以实现初始价格 P 的设置。在开放交易之后,结合第一部分我们讲到的不同类型的定价模型,资产的价格会根据流动性池中资产的数量不断变化。从上我们可以看出,自动做市商制度打破了传统的交易制度模式,不需要订单薄,也不需要做市商报价或者系统撮合,而是利用储备池中的流动性来完成资产的交易兑换;最重要的是,AMM 的交易价格也不是由做市商的报价或交易者的订单确定,而是由资产池中两种资产数量的比值确定,因此它是一种流动性驱动的交易制度。潜在风险:无常损失由于模型设计上的缺陷,AMM 不得不引入套利机制以完善其价格机制。然而,这也带来了另一个严重后果---无常损失(Impermanent Loss)无常损失实际上来源于套利行为。我们前面提前,AMM 的交易价格与市场公允价格是脱轨的,为此需要套利者进来购买被低估的资产或卖出高估的资产,直到 AMM 提供的价格跟外部市场匹配。因此,套利者的利润实际上来自于流动性提供者,由于套利给流动性提供者带来损失的这一部分就被称为无常损失。以下图为例 T3时刻套利发生后流动性池内总资产价值相比市场实际价值缺失,这部分价值就是套利者从流动性提供者处赚取的价值。流动性提供者(LP)之所以为 AMM 提供流动性,是因为可以获取交易费用,然而无常损失的存在,提高了流动性提供者的风险。如果无常损失超过了流动性收益,那么 LP 将不再提供流动性。因此无常损失的大小是决定 AMM 类 DEX 能否正常运营的关键。多代.币敞口AMM通常要求流动性提供者(LP)存放两种不同的代币,以在交易双方提供相等的流动性。因此,流动性提供者(LP)无法将其长期风险敞口保持在单一代币上,而是必须通过持有额外的ERC20储备资产来分割其敞口。拥有大量一种代币的团队,或希望提供流动性的个人持有者,被迫购买另一种资产才能提供流动性,从而减少他们在资产池基础代币中的持有量,并增加对另一项资产的敞口。3、优劣势优势分析:AMM的优势是显而易见的,他的出现与人们在defi市场追求去中心化,自动化,交易快捷的需求不谋而合,目前defi市场绝大多数的交易量都发生在应用了AMM的DEX上,充分体现了用户对这种交易模型的信任。DEX也是目前defi市场上可用性最高的交易数字货币的交易类型,然而目前AMM机制也存在着许多的问题,在某些方面相比传统的中心化竞价,做市商机制还存在着短板,这些方面也是目前市场上的AMM项目未来着力解决的方向,这里将做总结。劣势分析:无法独立定价我们前面提到,AMM 的价格是靠流动性驱动的,交易价格由储备池的资产情况决定,而非订单价格决定,即 AMM 只能产生交易价格,却不能发现市场价格。为此,AMM 不得不引入套利者这一重要角色:一旦 AMM 平台上的价格与市场公允价格不同,就会出现套利空间,并将价格拉回正轨。这意味着如果没有市面上的中心化交易所的存在,使用AMM的交易平台无法反映真实的资产价格,因此它无法完全替代现有的竞价制度和做市商制度。交易深度(滑点):交易深度是衡量市场交易优劣的重要指标之一,反映的是市场在承受大额交易时价格不出现大幅波动的能力。很多行业人士认为,只要向市场提供足够的流动性,就可以解决交易深度问题。对于以订单薄为基础的竞价制度和做市商制度确实如此,但对于 AMM 而言,其模型本身也会影响交易深度。相较于传统交易制度,在提供相同流动性的情况下,AMM 用户向交易合约中放入越多数量的资产 A,换回的资产 B 数量越少,即交易价格越高。所以 AMM 的交易深度不仅仅取决于 LP 的大小(即 k 值),跟模型本身也有关。因此,尽管 很多DEX 简洁的交易模型给其带来了巨大优势,但同时也带来了高滑点的问题。特别是对于储备池规模较小的交易对资产,无法支持大额交易,否则将支付更高的价格。资本效率低下: 由于AMM在整个价格范围(0,+∞)上均匀地分配资金,因此只有在市场价格附近分配的资金才能得到有效利用,而很大一部分资金只有在定价曲线开始呈指数变化时才可用。结果,AMM需要大量的流动性以匹配传统订单簿交易中的滑点。不过uniswap的V3在原有的基础上通过对做市机制的改革,极大的提升了资本效率。且以最新的消息来看,uniswap还将通过拆分大额订单的形式来提高大额交易的成交效率。可以期待~4、代表产品及其经济体系设计目前市场上有许许多多应用AMM机制的DEX产品,他们的交易量占据了Defi市场的大头,这里将选择市场中具有代表性的几个产品进行分析。主要包括其所使用的定价模型,经济体系,以及这些产品的优势和特点在哪里(他们着力于哪一方面)根据CoinMarketcap 当前 DEX交易量前十位分别为:1.Uniswap(V3)Uniswap自上线以来就占据着DEX交易龙头的宝座,也是他的出现将AMM引入defi世界,在这个过程中这个项目也经过了许多的更新,Uniswap基本代表着AMM DEX项目的标准,其他项目多是在Uniswap基础上进行的修正和改进。Uniswap自身也在不断进行版本迭代,前不久V3刚刚上线,这里将使用其最新版本进行研究。定价模型恒定乘积 (x * y = k)经济体系UNI是Uniswap协议的原生代币,为持有者赋予治理权。这意味着UNI持有者可以对协议变更投票表决。这款代币的初始铸造总量为10亿枚,其中60%由现有的Uniswap社区成员共享,其余40%将在四年内发放给团队成员、投资者和顾问。同时部分UNI可由流动性挖矿获得,这些代币将发放给为流动性资金池的供应商,激励他们提供流动性。特性Uniswap V3最大的改进实际上是通过集中流动性机制提升资本效率集中流动性在Uniswap的流动性资金池中,流动性供应商(LP)所提供的流动性对应的价格曲线实际上是从0到无穷大。所有这些资金均存放其中,应对池内其中一项资产出现5x-s、10x-s或100x-s的情况。如果出现这种情况,这些闲置资产将确保价格曲线的相应部分仍具流动性。这意味着资金池中只有一小部分流动性聚集在达成大多数交易的价格区间。如今,流动性供应商可以自行为注入流动性的资金池设定价格范围。因此,流动性会更加集中到大多数交易活动对应的价格范围。大大提升了资本效率Uniswp V3实现流动性聚集的原理也十分简洁:主要在V2版本的基础上增加了两个参数,(x+m)*(y+n)= km= L/√(p_b )n= L √(p_a )L^2=k在Uniswap V3中, x和y为实际储备资产,(x+m)和(y+n)为虚拟资产,虚拟资产等同于V2版本(x^'*y^'=k)中的x^'和y^'。例如在V2版本中,x^'和y^'的数量分别为300和600,在V3版本中,若m为100,n为200,那么x,y只分别需要200和400即可。从上我们可以发现,在保证模型流动性与V2版本一致的前提下,V3版本减少了x和y资产的实际数量需求,由此提高了资本效率。2.PancakeSwapPancakeswap运行在BSC上,可以看作是binance的DEX版本,从核心上与Uniswap并无太大区别和其他的 AMM 交易所类似,Pancake交易手续费为 0.2%,其中 0.17%作为流动性挖矿奖励,0.03%作为系统收入。Pancakeswap 就像是去中心化版的币安,除了交易类业务之外,还有诸多其他附属功能。这些功能的组合,让 Pancakeswap 不再是一个单纯的 DEX,而是一个综合性的 DeFi 服务平台。3.MDEX与Pancake类似,MDEX背靠HECO,同样拥有很高的交易量,MDEX的交易手续费为0.3%。比较特殊的是MDEX支持交易挖矿,用户可以通过交易获取MDX代币SushiswapSushiswap 是Uniswap的 fork ,其从DEX本身来说并无差异,他的不同处在于DEX之外的运营,治理策略。与Uniswap专注于swap本身及其流动性机制的改善,而Sushi更倾向于拓展有助于增加其流动性的其他功能和业务。4.Curve(V2)正如之前我们提到的那样,Curve采用了混合型CFMM的机制,创造了一种曲线,这种曲线在其核心范围内具有恒定和的无滑点稳定的特性,又在曲线两端保证了流动性的存在,这样的机制是的其能够为稳定币在DEX上的交易提供极低的滑点同时,保证了流动性。V2 曲线同时在最新发布的V2版本中,项目又对曲线作出了改进:这个最新的数学模型最核心的部分是其创造了一条全新形态的曲线。从上图直观来看,两条虚线是恒定乘积曲线,蓝色线是著名的Curve V1稳定币兑换曲线,而Curve V2构造的黄色曲线具备两个基本特征——(1)介于恒定乘积曲线和Curve V1曲线之间;(2)其曲线尾部特征拥有明显的恒定乘积曲线拟合。所以它可以解决什么问题:(a)继承了Curve V1在“均衡点”附近区域超低滑点和聚集流动性的优势;(b)通过介于恒定乘积曲线和Curve V1曲线之间,以及在曲线的中尾部区域向恒定乘积曲线拟合,获得恒定乘积曲线快速响应流动性变化的优势,避免池子流动性枯竭,灵活响应快速的市场变化。除此之外还有一个很重要的创新:内部预言机repegging机制。这项机制对实施更好的集中流动性以及减缓无常损失是十分有利的。简单的说这项机制使得原本固定的Curve V1曲线便会随着场内汇率的大偏移不断变换均衡点,使得永远在当前汇率附近具备最大的流动性,及时对抗套利者,减缓无常损失。可以看到Curve用非常复杂的数学模型创造出一条能够在恒定乘积曲线和恒定和曲线之间动态平衡的曲线,使得在Curve上的稳定币交易能够兼具两条曲线低滑点和高流动性的特性。同时新的引入机制一定程度上解决了无常损失,资本效率等问题,团队的数学能力是他们的核心竞争力。Curve的激励机制除了上文我们提到由于Curve独特的曲线设计而拥有的低滑点,无常损失低之外,Curve创立之初就以低廉的交易手续费为卖点,但是这样就造成LP的收益相应降低,为此Curve拥有与大多数DEX不同的流动性激励机制。AMM是基于流动性流动性驱动的交易模型之一,虽然并非区块链生态原创,但是缺在区块链生态当中发展壮大。究其原因,我们认为有以下几点:1:简洁的定价和做市模型降低了流动性汇聚的门槛2:uniswap等产品无审查无限制且产品化程度较高的上币机制促进了其野蛮生长3:简洁的UI和产品逻辑降低了用户的使用门槛4:开源精神促进了组合式创新的演进5:流动性挖矿机制促进了AMM的需求DeFi的可组合性给AMM赋予了新的意义,那就是“基础设施”,在DeFI乐高的整体生态里,AMM和借贷,保险,合成资产等产品发挥了基础设施的作用,多种类型产品的组合也激发了更多的创新。创新的同时也面临着金融风险与合规风险的压力,尤其是最近Uniswap前端下架股票类通证这一事件,也引发了很多从业者对监管的担忧。好在这种担忧更多是针对项目方的,DeFi生态本质不受影响,未来仍旧可期。之后,先知实验室还会向大家分享其他的交易模型在DeFi生态的实践,保持关注吧~关于SeerLabs:SeerLabs(先知实验室)是一家亚洲领先的专注区块链市场孵化的机构,我们拥有全球前沿营销理念和增长黑客,致力于帮助项目方和初创公司实现闪电性的快速增长。成功深度参与孵化了Ploygon(MATIC),http://HoDooi.com,DIA,Paralink,Swingby,XEND Finance,BOSON等30+项目。风险提示:数字资产是一种高风险投资标的,请广大公众理性看待区块链,提高风险意识,树立正确的货币观念和投资理念。发布于 2021-07-30 11:21科普赞同 91 条评论分享喜欢收藏申请转载文章被以下专栏收录先知实验室In Blockchain we tru
AMM - 知乎
AMM - 知乎首页知乎知学堂发现等你来答切换模式登录/注册AMM自动化做市商(automated market maker)是一种去中心化交易平台(DEX)协议,通过数学公式对资产进行定价。资产定价通过定价算法完成,不再使用传统交易平台常用的订单薄。查看全部内容关注话题管理分享简介讨论精华视频等待回答切换为时间排序区块观察随笔(2):AMM情境下的MEV用例摸圾狸游戏玩家/计算机技术爱好者/打工厂仔引言各位读者们好,这里是摸圾狸的个人学习总结笔记,不构成任何投资广告建议,如有错误疏漏感谢各位指出。 关注过ETH2.0科普的朋友应该听说过MEV(矿工可提取收益)的概念,通俗地说就是矿工检查等待打包的交易池并通过某些手段(比如排序交易、插入交易等)从中获取利益的行为。但这样的描述并不能让笔者十分理解MEV的实际概念,本文于是记录一下最近读到的AMM(自动做市商)情境下的一种MEV应用。 背景设置先简要交代一下自动…阅读全文赞同 1添加评论分享收藏AMM最新评论|张有为教授和“激酶之王”院士-PI3K驱动肿瘤的新证据国际科学编辑25年专业SCI论文润色平台 微信号:13222996274[图片] 近日, 美国凯斯西储大学医学院药理系张有为副教授团队和美国科学院院士、加州索尔克研究所的Tony Hunter教授合作,在Acta Materia Medica上发表了题为“The ‘New (Nu)-clear’ evidence for the tumor-driving role of PI3K”的评论文章,对最近Hao Y等人发表于Nature Communications上的一篇有关PI3K在癌症发展中的新发现文章进行了深入的点评及引申讨论(http://doi.org/10.15212/AMM-2022-0013 )。 [图片] PI3K是一类高度保守的脂质磷酸激酶。跟传…阅读全文赞同 2添加评论分享收藏去中心化与中心化交易所的区别|什么是自动做市商AMM?|什么是无常风险?善一视角区块链科普系列第六期:
中心化交易所(CEX)与去中心化交易所(DEX)的优劣势对比以及不同
什么是做市商?什么又是自动做市商(AMM)?
什么是无常损失?
什么是恒定函数做市商模型?
--------------------------…阅读全文赞同 42 条评论分享收藏喜欢 举报什么是(AMM)自动做市商?视频详解老鹰看行情专注深耕加密领域,公号:飞鹰Community阅读全文赞同添加评论分享收藏喜欢 举报AMM最新评论|张有为教授和“激酶之王”院士-PI3K驱动肿瘤的新证据国际科学编辑25年专业SCI论文润色平台 微信号:13222996274[图片] 近日, 美国凯斯西储大学医学院药理系张有为副教授团队和美国科学院院士、加州索尔克研究所的Tony Hunter教授合作,在Acta Materia Medica上发表了题为“The ‘New (Nu)-clear'evidence for the tumor-driving role of PI3K”的评论文章,对最近Hao Y等人发表于Nature Communications上的一篇有关PI3K在癌症发展中的新发现文章进行了深入的点评及引申讨论(http://doi.org/10.15212/AMM-2022-0013 )。 [图片] PI3K是一类高度保守的脂质磷酸激酶。跟传统…阅读全文赞同添加评论分享收藏祛魅做市商区块链研究员区块链行业,咨询,方案设计,技术研发,安全方面(挽损)等FTX 爆雷,帝国坍塌,一系列头部平台遭受重创,做市商和借贷成为重灾区: Alameda 作为加密货币行业最大的做市商之一,在这场闹剧中覆灭,并于 11 月 10 日正式结束交易;DCG 旗下做市商和贷款公司 Genesis,也在面临偿付能力不足困境。 头部做市商坍塌,大量本金覆灭,急剧的单边行情……这引起了行业做市商的空前恐慌,余震中,做市商趋于停摆,社区和项目面临巨大压力测试,加密行业的市场流动性遭遇大幅下降。 无论传统市场…阅读全文赞同添加评论分享收藏「入门科普 」DeFi 未来:完美的 AMM 应该是什么样的?BTX Research全球卓越的技术研究机构,分享前沿的国际化视角的Web3研究原文作者:Joe Content 编译:BTX Capital 通过前两篇文章的介绍,我们已经了解了第一代 AMM 和第二代 AMM ,是时候来设想一下一个完美的 AMM 应该是什么样的了。作者认为一个完美的 AMM 应该具备以下要素:零滑点交易、多样化的代币种类、安全、不依赖外部各方和代币发行、无许可创建流动资金池以及被动流动性管理。利益相关者 当用户说他们想要从 DEX 中获得些什么时,他们通常是在给出他们想要什么的看法。但他们没有意识到的…阅读全文赞同 1添加评论分享收藏iZUMi 开创的 DL-AMM:基于UniSwap V3 思路的改进HLM 名述金融沉浸者,Otcva Labs原文作者:JoJonas 原文来源:Biteye 自 Uniswap 推出 V3 版本一年半有余,其所提出的「聚合流动性」概念已被用户习以为常。 目前 Uniswap 官网提供的分析数据中,V3 的 TVL 约是 V2 的 3 倍以上,日交易量则在 10 倍以上。 https://info.uniswap.org/#/ 集中流动性使得用户可以主动选择其提供流动性的价格范围,显著提升了 V3 的 LP 资金效率,但其并未改变定义 LP 的恒定乘积公式,也就是说,无常损失仍然存在,并随着资金效率提升而相…阅读全文赞同 1添加评论分享收藏平头哥【Ratel swap】对【AMM自动做市商】原理的深度认知xiaodingchaobi1AMM做市原理是去中心化金融领域Swap的伟大创新,伟大主要来自两个原因:机制的改革让个体可以参与,成为做市商,把原本中心化交易所的手续费以及通证增值的红利按贡献通过智能合约分配给参与者,其二,通过区块链智能合约技术,公开透明,所有交易记录在链上,真实交易,解决了信任问题,杜绝了中心化交易所随时做恶的可能! 你还记得曾经一家交易所挂出2100万枚大饼在卖的场景吗?! 2AMM自动做市原理类似一个合约形成自动量化…阅读全文赞同添加评论分享收藏ahr999-AMM智能基金池TomLiu 刘秋杉杭州时戳信息科技有限公司 首席研究员摘要:探索一种具备(指数)基金性质的新型 AMM【1】,兼获阿尔法收益(AMM 手续费收益)和贝塔收益(被动跟随市场牛熊收益)。 AMM与指数基金我们发表了对 DeFi 指数基金的思考和认知 ——《论再平衡:DeFi实现指数基金的正确方式》【2】,在这篇文章里,我们提出了一种更为复杂的 AMM 策略控制,我们认为基于 AMM 实现指数基金的思想是值得一试的,也是如今头部 AMM 项目很有可能在未来去集成的创新特征,因为 AMM 和指数基金…阅读全文赞同 1添加评论分享收藏如何理解Dex中的无常损失?Web3大航海Web3 / 区块链投研分析 & 社区无常损失原理详解将一对资金存入Uniswap等的流动性池中,成为流动性提供者(LP),获得收益回报,我们要考虑的最大风险是所谓的无常损失(impermanent loss)。 我更认同这个准确的说法应该是发散损失(divergence loss),但这里我们也接受约定俗成的说法说是无常损失,也就是如果价格波动然后又回归,你看起来只是经历了暂时的损失,而不是永久的损失。 那么,无常损失究竟是怎么回事呢?在这篇短文中,我来为你介绍一下。 ▍…阅读全文赞同 1添加评论分享收藏浏览量5.1 万讨论量28 帮助中心知乎隐私保护指引申请开通机构号联系我们 举报中心涉未成年举报网络谣言举报涉企虚假举报更多 关于知乎下载知乎知乎招聘知乎指南知乎协议更多京 ICP 证 110745 号 · 京 ICP 备 13052560 号 - 1 · 京公网安备 11010802020088 号 · 京网文[2022]2674-081 号 · 药品医疗器械网络信息服务备案(京)网药械信息备字(2022)第00334号 · 广播电视节目制作经营许可证:(京)字第06591号 · 服务热线:400-919-0001 · Investor Relations · © 2024 知乎 北京智者天下科技有限公司版权所有 · 违法和不良信息举报:010-82716601 · 举报邮箱:jubao@zhihu.
什么是AMM?聊聊靠简单数学公式打造的金融独角兽 | 登链社区 | 区块链技术社区
什么是AMM?聊聊靠简单数学公式打造的金融独角兽 | 登链社区 | 区块链技术社区
文章
问答
讲堂
专栏
集市
更多
提问
发表文章
活动
文档
招聘
发现
Toggle navigation
首页 (current)
文章
问答
讲堂
专栏
活动
招聘
文档
集市
搜索
登录/注册
什么是AMM?聊聊靠简单数学公式打造的金融独角兽
celia
更新于 2021-06-07 00:44
阅读 5368
恒定乘积听着听拗口的,说人话就是两个变量相乘得到一个固定常数。这样一个简单的乘法公式怎么完成“做市”这种深奥的金融业务?
AMM是Automated Market Maker的缩写,中文名字叫自动做市商。往简单了说,就是由一个算法代替传统中心化交易所的位置,为市场上的交易提供流动性的平台。
市场上的交易者因为对市场的预期不同,手里持有资产的不同,每个交易者都有不同的交易需求。我们都知道要成为传统的做市商需要具备非常雄厚的资金,才能不断通过成为市场上交易对的卖方和买方,整合交易,从而让散户不用在交易时不断等待对手盘的出现。
区块链各种虚拟币的交易最初也靠中心化交易所起家。这一切的平静被UNISWAP打破,而且UNISWAP运用的方法简单到令人大跌眼镜——恒定乘积原理。
```
x * y = k
```
恒定乘积听着听拗口的,说人话就是两个变量相乘得到一个固定常数。这样一个简单的乘法公式怎么完成“做市”这种深奥的金融业务?
这一机制正常运转的背后由三种角色,分别是:
1交易者:用一种资产交换另一种资产
2流动性提供者(LP) :愿意将自己的资产组合贡献出来,帮助他人进行交易,获得一定费用
3套利者:发现价值凹地,比如从UNISWAP中低价买入到市场上去卖出,以赚取一定利润
UNISWAP官网中用一张图详细地描述了三者的关系:
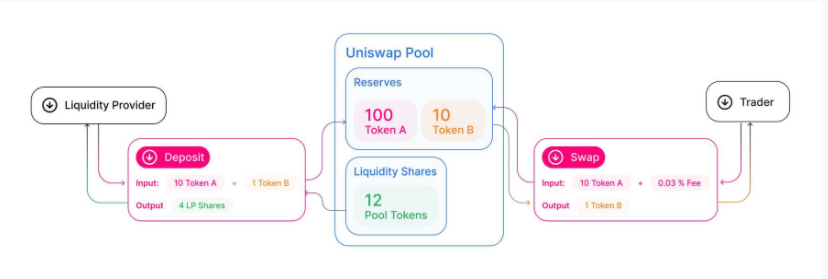
当然图中是没有套利者的,因为从平台的角度看,两者产生的都属于交易行为。
我们假设UNISWAP一个交易池中是ETH-DAI,第一个流动性提供者放进去了a个ETH和bb个DAI。
这时候这个交易对,对应的初始值是 x=a, y=b;那K的初始值=a*b;
此时ETH的价格就是b/a,DAI的价格=a/b;
在K不变的情况下,如果这个交易池有trader T进来,想用w个EHT换DAI。他会以什么样的价格拿到多少DAI呢?
在恒定乘积下,这个运算过程是这样的:
```
y’=K/(x+w)
```
其中y’等于此次交易后,交易池中的DAI的个数。由此可知,T得到的DAI的个数=y-y’;这些DAI的价格=w/(y-y’).
所以你发现了吗?在交易者告诉平台自己要兑换的数量之前,他能拿到什么价格是不确定的。这就让UNISWAP的价格获取跟中心化交易所和利用价格预言机的交易所完全区分开了。
还有别忘了,我们假定的前提条件是K不变,那哪些情况下K值是要改变的?答案有二,一是交易费,二是流动性。
**交易费**
用户每一次的交易,需要交0.3%的手续费。拿上面交易举例,我们为了简化计算忽略了手续费,真实的情况是uniswap平台在计算出y’后会扣除0.3%y’的手续费,完成交易后,这0.3%dy会被添加到流动性池里,此时K值就变成了 x*y+x*0.3%y’=x*(y+0.3%y).
所以,你发现了吗?K值变大了。反之亦然,减少流动性,会减少K值。换言之,恒定乘积算法的K值并不恒定,每一笔交易都会影响K值。
**流动性**
流动性是怎么改变K值的呢?当第二个人在一个交易对中按照比例增加了ETH和DAI的数量,X和Y就同时增加了,很显然,K的值就是增加的;如果第一个人取走自己的交易对,K值就减少,非常简单。
总之呢,“恒定”乘积针对的是总体流动性不变的情况下,也假设没有手续费的时候,K是不变的,就像计算物理题的时候假设某个状态下不存在摩擦力一样。通过简化前提,让这样一个简单的乘法就实现了价格与供应量成反比的经济学原理,真可谓是天才设计了。
但是习惯了传统做市商模式的你可能会不习惯,这种对两种资产进行定价的方式,不仅少见还显得过于独断。让两种代币的库存数相乘所得的积维持固定,为什么就能确保正确的报价呢?因为设计者相信市场中始终存在聪明的套利者,会反复交易,直到平台价格与真实价格相符无利可图。
诚然,恒定成绩做市商模式因为缺乏与外界的联动显得略微被动和孤立,总是需要套利者去抹平平台上价格与真实价格之间的差;而且被大家诟病的交易滑点和LP(流动性提供者)无偿损失也阻碍着更加保守的交易者进入这个领域。
但它的优点也是显而易见的,高效、透明、维护成本低,降低了做市门槛等都让它的缺点显得不那么重要了。
用一句话总结就是——“一切交给市场”。
自从UNISWAP开创了AMM自动做市商模式,仿佛给区块链大佬们开了脑洞一般,越来越精细化的项目进来做市商的赛道。虽然去中心化金融产生的时间不长,但是这其中爆发的创造力十分惊人,而来会有哪些四两拨千斤的金融项目?我们拭目以待。
AMM是Automated Market Maker的缩写,中文名字叫自动做市商。往简单了说,就是由一个算法代替传统中心化交易所的位置,为市场上的交易提供流动性的平台。
市场上的交易者因为对市场的预期不同,手里持有资产的不同,每个交易者都有不同的交易需求。我们都知道要成为传统的做市商需要具备非常雄厚的资金,才能不断通过成为市场上交易对的卖方和买方,整合交易,从而让散户不用在交易时不断等待对手盘的出现。
区块链各种虚拟币的交易最初也靠中心化交易所起家。这一切的平静被UNISWAP打破,而且UNISWAP运用的方法简单到令人大跌眼镜——恒定乘积原理。
x * y = k
恒定乘积听着听拗口的,说人话就是两个变量相乘得到一个固定常数。这样一个简单的乘法公式怎么完成“做市”这种深奥的金融业务?
这一机制正常运转的背后由三种角色,分别是:
1交易者:用一种资产交换另一种资产
2流动性提供者(LP) :愿意将自己的资产组合贡献出来,帮助他人进行交易,获得一定费用
3套利者:发现价值凹地,比如从UNISWAP中低价买入到市场上去卖出,以赚取一定利润
UNISWAP官网中用一张图详细地描述了三者的关系:
当然图中是没有套利者的,因为从平台的角度看,两者产生的都属于交易行为。
我们假设UNISWAP一个交易池中是ETH-DAI,第一个流动性提供者放进去了a个ETH和bb个DAI。
这时候这个交易对,对应的初始值是 x=a, y=b;那K的初始值=a*b;
此时ETH的价格就是b/a,DAI的价格=a/b;
在K不变的情况下,如果这个交易池有trader T进来,想用w个EHT换DAI。他会以什么样的价格拿到多少DAI呢?
在恒定乘积下,这个运算过程是这样的:
y’=K/(x+w)
其中y’等于此次交易后,交易池中的DAI的个数。由此可知,T得到的DAI的个数=y-y’;这些DAI的价格=w/(y-y’).
所以你发现了吗?在交易者告诉平台自己要兑换的数量之前,他能拿到什么价格是不确定的。这就让UNISWAP的价格获取跟中心化交易所和利用价格预言机的交易所完全区分开了。
还有别忘了,我们假定的前提条件是K不变,那哪些情况下K值是要改变的?答案有二,一是交易费,二是流动性。
交易费
用户每一次的交易,需要交0.3%的手续费。拿上面交易举例,我们为了简化计算忽略了手续费,真实的情况是uniswap平台在计算出y’后会扣除0.3%y’的手续费,完成交易后,这0.3%dy会被添加到流动性池里,此时K值就变成了 xy+x0.3%y’=x*(y+0.3%y).
所以,你发现了吗?K值变大了。反之亦然,减少流动性,会减少K值。换言之,恒定乘积算法的K值并不恒定,每一笔交易都会影响K值。
流动性
流动性是怎么改变K值的呢?当第二个人在一个交易对中按照比例增加了ETH和DAI的数量,X和Y就同时增加了,很显然,K的值就是增加的;如果第一个人取走自己的交易对,K值就减少,非常简单。
总之呢,“恒定”乘积针对的是总体流动性不变的情况下,也假设没有手续费的时候,K是不变的,就像计算物理题的时候假设某个状态下不存在摩擦力一样。通过简化前提,让这样一个简单的乘法就实现了价格与供应量成反比的经济学原理,真可谓是天才设计了。
但是习惯了传统做市商模式的你可能会不习惯,这种对两种资产进行定价的方式,不仅少见还显得过于独断。让两种代币的库存数相乘所得的积维持固定,为什么就能确保正确的报价呢?因为设计者相信市场中始终存在聪明的套利者,会反复交易,直到平台价格与真实价格相符无利可图。
诚然,恒定成绩做市商模式因为缺乏与外界的联动显得略微被动和孤立,总是需要套利者去抹平平台上价格与真实价格之间的差;而且被大家诟病的交易滑点和LP(流动性提供者)无偿损失也阻碍着更加保守的交易者进入这个领域。
但它的优点也是显而易见的,高效、透明、维护成本低,降低了做市门槛等都让它的缺点显得不那么重要了。
用一句话总结就是——“一切交给市场”。
自从UNISWAP开创了AMM自动做市商模式,仿佛给区块链大佬们开了脑洞一般,越来越精细化的项目进来做市商的赛道。虽然去中心化金融产生的时间不长,但是这其中爆发的创造力十分惊人,而来会有哪些四两拨千斤的金融项目?我们拭目以待。
学分: 11
分类: DeFi
标签:
AMM
点赞 3
收藏 4
分享
Twitter分享
微信扫码分享
你可能感兴趣的文章
基于 SCP 范式构建,DEX 可以实现「AMM 自由」
481 浏览
Midaswap:挂单 or 添加 LP,NFT 流动性的全新视角
5175 浏览
Trader Joe V2: 也许是未完成的 “Uniswap V4” 应有的模样
1553 浏览
Caspian —— 一种由 Layer 2 驱动的新型 AMM 设计
2128 浏览
相关问题
0 条评论
请先 登录 后评论
celia
关注
贡献值: 47
学分: 38
江湖只有他的大名,没有他的介绍。
文章目录
关于
关于我们
社区公约
学分规则
Github
伙伴们
ChainTool
为区块链开发者准备的开源工具箱
合作
广告投放
发布课程
联系我们
友情链接
关注社区
Discord
Youtube
B 站
公众号
关注不错过动态
微信群
加入技术圈子
©2024 登链社区 版权所有 |
Powered By Tipask3.5|
粤公网安备 44049102496617号
粤ICP备17140514号
粤B2-20230927
增值电信业务经营许可证
×
发送私信
请将文档链接发给晓娜,我们会尽快安排上架,感谢您的推荐!
发给:
内容:
取消
发送
×
举报此文章
垃圾广告信息:
广告、推广、测试等内容
违规内容:
色情、暴力、血腥、敏感信息等内容
不友善内容:
人身攻击、挑衅辱骂、恶意行为
其他原因:
请补充说明
举报原因:
取消
举报
×
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
【赛博朋克2077】终于可以自定义NPC姿势辣!AMM重磅更新2.0版角色外观修改菜单_哔哩哔哩bilibili_赛博朋克2077
【赛博朋克2077】终于可以自定义NPC姿势辣!AMM重磅更新2.0版角色外观修改菜单_哔哩哔哩bilibili_赛博朋克2077 首页番剧直播游戏中心会员购漫画赛事投稿【赛博朋克2077】终于可以自定义NPC姿势辣!AMM重磅更新2.0版角色外观修改菜单
5.0万
80
2022-12-20 22:20:46
未经作者授权,禁止转载96043093537一群:757538483,二群:125625988,整合包每日更最新mod
偷偷说一嘴,内个姿势是有的噢~..
BGM:The Kiffness - Alugalug Cat,Kasbo - Places We Don't Know这MOD就离谱游戏单机游戏模组赛博朋克MOD赛博朋克2077单机游戏steam整合教程攻略来亿点MOD 第八期
账号已注销
发消息
关注 1.0万
拒绝低效率学习,高效提高GPA!
【赛博朋克2077】模组整合
(10/15)自动连播191.7万播放简介
订阅合集
新任务模组
10:31
1.61.1整合包+99%汉化
22:22
自用捏脸数据分享
04:00
真·幻化衣柜系统模组
06:13
E3 2018界面ui模组
05:18
更多服装+NPC美化
09:28
汉化模组整合三
10:04
汉化模组整合二
12:47
汉化模组整合一
19:52
AMM外观修改菜单教程
05:24
时停超级跳教程
02:50
空中超级跳教程
03:33
1.61整合包+90%汉化
24:10
1.6整合包+50%汉化
30:01
整合伪预告
04:21
【赛博朋克2077 2.0】一秒教会你让你喜欢的人和你一起难忘今宵!最强大的mod!没有之一!!!_鹿茸_
8320
0
赛博朋克2077(推倒)蓝月-开往春天的高铁-
93.3万
352
2077个人捏脸分享桜は心
84.0万
426
【赛博朋克2077】NPC攻略:把酒吧小姐姐抱回家梦遥无归期
4.3万
9
长发甜美女V捏脸-2.0版本往日之影-赛博朋克2077玩儿就一个字
18.1万
31
【赛博朋克mod制作】尝试制作替换NPC的mod——以帕南、奥萝尔为例迪奥布兰度Official
3005
2
2077终于能用第三人称了!赛博朋克2077我是小煜XY
23.3万
307
赛博朋克2077露西捏脸预设及MOD安装教程路薰
9.1万
11
赛博朋克20771.63/1.63热更新模组整合小MOscovin
13.2万
32
2077更加真实的第一人称!低头就是福利!我是小煜XY
39.3万
380
公寓换肤!车辆换肤!2077最强MOD AMM玩地球ol不能主动下机
1.9万
20
[赛博朋克2077]自定义一切!神级mod脚本引擎国内汉化首发!支持任务自定义与派系自定义!机智的迈克尔
33.4万
258
【赛博朋克2077】女V“传说套装”外观一只路过的300金
10.1万
51
【赛博朋克2077】 最新1.61版本 10个真香modcindy_silence
6.6万
144
【赛博朋克2077】外观十分帅气的传说外套[夜游鬼拉力博莱罗夹克]的获取位置很想带你去吹吹风i
3.4万
9
赛博朋克2077,教你如何找个女朋友带回家阿程游戏分享
9.1万
14
【赛博朋克2077】NPC召唤mod更新,人物载具改变外观modT提莫希T
8163
1
《赛博朋克 2077》永远可以相信玩家做的皮肤DLCKpo_84
9.5万
62
【赛博朋克2077更新日志 2.02版本】整合包发布 关于第一人称衣服BUG+天气切换MOD+AMM配合拍照模式食用(眼睛看镜头)PryexKarma
1.1万
3
赛博朋克2077mod安装指南入门篇-CET&AMM入门教程-1.5x版本CET与1-13-2b版本AMM竹筒狸猫sigmaraccoon
2.8万
6
展开
小窗
客服
顶部
赛事库 课堂 2021
中国力学类及应用数学类SCI影响因子最高!这本国际期刊,由上大老校长钱伟长院士创办|力学|钱伟长|中国_新浪新闻
中国力学类及应用数学类SCI影响因子最高!这本国际期刊,由上大老校长钱伟长院士创办|力学|钱伟长|中国_新浪新闻
新浪首页
新闻
体育
财经
娱乐
科技
博客
图片
专栏
更多
汽车教育时尚女性星座健康
房产历史视频收藏育儿读书
佛学游戏旅游邮箱导航
移动客户端
新浪微博
新浪新闻
新浪财经
新浪体育
新浪众测
新浪博客
新浪视频
新浪游戏
天气通
我的收藏
注册
登录
新闻中心
国内新闻>正文
新闻
图片
视频
中国力学类及应用数学类SCI影响因子最高!这本国际期刊,由上大老校长钱伟长院士创办
中国力学类及应用数学类SCI影响因子最高!这本国际期刊,由上大老校长钱伟长院士创办
2021年07月30日 10:25
上海大学
缩小字体
放大字体
收藏
微博
微信
分享
0
腾讯QQ
QQ空间
原标题:中国力学类及应用数学类SCI影响因子最高!这本国际期刊,由上大老校长钱伟长院士创办 来源:上海大学 2021年7月30日,纪念老校长钱伟长先生逝世十一周年 科技期刊的国际影响力 是国家科技竞争力的重要标志 培育世界一流科技期刊的重要性 不言而喻 而这份重要性 我们的老校长钱伟长先生 早在上世纪80年代就已充分认知 2021年7月30日 是钱伟长先生逝世十一周年的日子 今天,我们要来说说钱老与上大期刊 Applied Mathematics and Mechanics (English Edition)的故事 中国近代力学的创始人之一——上海大学原校长钱伟长院士创办的Applied Mathematics and Mechanics (English Edition)(以下简称“AMM”),至今已有41年的历史,在国内外力学、应用数学界具有广泛学术影响。AMM现为月刊,每月出版纸质版和在线电子版,由上海大学和中国力学学会联合主办,由Springer-Nature公司全球发行。钱先生对AMM钟爱有加,一直把期刊当成他人生中疼爱的“孩子”。 创刊人钱伟长院士审读AMM AMM创刊伊始就坚持高起点、国际化。编委会成员遍布学术水平发达地区,现任编委中,有美、英、法、以、俄、中等国内外院士编委25人;从1980年创刊至今一直由国际出版公司发行。AMM于1990年被EI收录,1997年被SCI收录,现如今是SCI影响因子最高的中国力学类及应用数学类期刊,全球排名位列JCR的Q1区,2019年入选中国科协、国家新闻出版署等七部委组织的“中国科技期刊卓越行动计划”重点期刊,彰显了本刊的国际影响力和核心竞争力。 在艰难中诞生 为了国家的科技发展,为了促进应用数学与力学的交融,为了给国内外学术界提供一个交流互动的渠道,也为了培养更多的应用数学和力学人才,创办刊物一直是钱先生的宿愿,但是由于种种原因处处碰壁。直到1978年,形势才稍有转机,国家的科技政策发生了变化,是年已66岁的钱先生立意创办刊物。他百折不回,经过无数次尝试,硬是为刊物问世“杀岀了一条血路”,一年之后拿到了刊物的“准生证”。 在豪迈中创立 1978年,在钱伟长先生的号召下,很快就聚集起一支二三百人的队伍,组成了以专业组成员为核心的小组,开始筹备创刊。钱先生提出初步方案,英文刊物定名为Applied Mathematics and Mechanics (English Edition),属于力学基础研究类刊物;实行编委推荐制;编委会成员应是活跃在科研第一线的中青年学者,只看能力,不看资历。三十几位编委中,只有两位院士和少数几位知名教授,其余多为一线工作的副教授、讲师等。在极其艰苦的环境下,钱先生以巨人的气魄,号召全国有为的应用数学和力学人才聚集一堂,共襄盛举,开创了一份伟大的事业。 在成长中收获 作为主编,钱伟长先生事无巨细,亲力亲为。自创刊开始,他亲任主编,事必躬亲,严把刊物质量关,2002年改任名誉主编后依然关注和指导编委会的工作,曾先后为刊物撰写并发表论文40篇左右,审查推荐论文近500篇,每一期的稿件都要自己亲自审阅,直到90高龄。在他的率先垂范下,办刊没几年,AMM得到蓬勃发展并取得了引人瞩目的业绩,很快由季刊转为双月刊,继而转为月刊,这在当时的国内并不多见;办刊伊始就注重国际化的这本期刊,一直由海外机构国际推广和发行;成为我国最早的同时被SCI和EI收录的期刊之一;形成了强有力的编委会和稳定的作者群,最初的编委会成员中成就了16位国内外院士,15位校长、副校长乃至省长,大部分成员成为学术界和相关领域的中坚力量。 主编联席会 在传承中创新 时至今日,AMM已是国内应用数学和力学界最具国际影响力的期刊之一。作为一本专业性品牌期刊,AMM被国内外20多个知名数据库收录,并被美国力学科学院评为17种国际力学刊物之一。 编委会议 在主管单位上海市教委、主办单位上海大学和中国力学学会支持下,在继任主编周哲玮教授、郭兴明教授为首的编委会不懈努力,以及期刊社的大力支持下,依靠海内外专家学者共同努力,AMM获得“中国科技期刊国际影响力提升计划(PIIJ)(重点期刊)”“中国科技期刊卓越行动计划(重点期刊)”等重要国家级项目资助,在国际学术界的能见度和活跃力直线上升,目前是国内力学类和数学类SCI影响因子最高的期刊。 2021年AMM影响因子 今年6月30日,科睿唯安发布的期刊引证报告(Journal Citation Report)中显示,AMM的2020年度影响因子为2.866,在265种应用数学学科期刊中排名第30名,稳步保持在Q1区;在136种力学学科期刊中排名第54名,位列Q2区。AMM曾获得“国家期刊奖百种重点期刊”(国家新闻出版总署)、“中国高校精品科技期刊奖”(教育部,连续五届)、“百强报刊”(国家新闻出版广电总局)、“中国最具国际影响力学术期刊”(连续九届),以及“中国最美期刊”“中国高校科技期刊优秀网站”“中国高校优秀英文期刊”等多项荣誉。今年7月获得“第五届中国出版政府奖”提名奖。 AMM被推荐为“百强报刊” AMM获得第五届中国出版政府奖提名奖 老校长钱伟长先生是一面旗帜。他所坚持“国家的需要就是我的专业”的思想,将本刊的方向定位在应用数学和力学上,支持以国民经济建设为导向的学术研究;他放眼世界、高瞻远瞩,力主创办“外向型”刊物,将AMM打造成一个将国际国内成果“请进来,打出去”的顶尖平台;他不拘一格,敢于也善于扶持年轻人,把他们放在重要的岗位上,放手让他们在辽阔的土地上驰骋,使国家的应用数学和力学事业后继有人。 钱伟长先生敢为天下先,在创办符合自己理想的研究所的同时,又创办了自己最中意的刊物Applied Mathematics and Mechanics (English Edition)。AMM将继续在其办刊思想的指引下,牢记使命,自强不息,再创辉煌! 上海大学期刊社是全国高校期刊集约化管理实践的排头兵,在各级领导部门的关心和支持下,49名期刊人认真贯彻执行党和国家的各项方针政策,严格遵守国家期刊出版方面的法律法规,以质量求生存,以研究谋发展,主动适应全球化、信息化社会对编辑出版工作的要求,不断改革创新,打造精品期刊,取得跨越式发展和可喜的成绩。期刊社先后荣获中国出版政府奖先进出版单位、期刊奖等5项,目前是上海市教育系统唯一荣获“全国五一巾帼标兵岗”单位。获得省部级奖励60余项,承担国家级项目6项。目前有4种期刊入选SCI和SSCI数据库,其中3种位于Q1区;2种期刊入选ESCI数据库;4种期刊入选EI 数据库;6种期刊入选Scopus 数据库;2种期刊入选CSSCI数据库;5种期刊入选北大中文核心期刊。 大师风范,高山仰止 爱国奉献,伟业流长 “我没有自己的专业,祖国的需要就是我的专业” 会永远激励着一代又一代学子 茫茫宇宙中的“钱伟长星” 永远指引着上大人 砥砺前行、不断奋斗!
关键字 :
力学钱伟长中国老校长数学类
我要反馈
相关新闻
投资热点尽在新浪财经APP>
加载中
点击加载更多
阅读排行榜
评论排行榜
01
张家界、常德、株洲、长沙、益阳最新通报!
02
陈梦东京奥运夺冠!表哥黄晓明:礼物是“做顿饭”
03
新冠肺炎疫情严峻复杂,越南有点急了!
04
奥运今日看点:这两场巅峰对决,看着没压力
05
15个副省级城市人口:8城超千万,这4城新入围
01
意大利单日新增6557例确诊病例,累计确诊破5万
02
【新华财经】晋能控股集团按下“双碳”行动“快进键”
03
【深化省校合作 共促高质量发展】晋能控股电力集团每年600个就业岗位邀约高校人才
04
奥运女排小组赛 中国 VS ROC
05
奥运女排小组赛 中国 VS 美国
图片新闻
郑州公交免费乘坐
南京全员核酸检测
民众欣赏奥运圣火
校场:美F-35再遭雷劈 为何总受伤?
视频新闻
国乒奥运首金出炉
中国首款新冠病毒移动检测车
张家界关闭所有景区景点
殷墟部分考古工地遭雨水漫灌
热点博客
这才是油焖大虾最好吃的做法,简单易学,一起为奥运健儿加油
独具风味的盐水鸭,绝对值得一试
经济适用男,这是离婚女人的最佳选择吗
对于孩子来讲,不叛逆还怎么成长?
没有天鹅颈的女孩
不同避孕方法对于女性运动训练的影响
海外博主:我没有女朋友,没有私生活
新媒体实验室
朋友圈47%的内容在炫耀
近300起杀妻案如何判罚
谈恋爱反降低生活质量?
全国最能吃的省市竟是它
性犯罪者再犯几率达12.8%
新浪新闻意见反馈留言板
400-052-0066 欢迎批评指正
新浪简介
|
广告服务
|
About Sina
联系我们
|
招聘信息
|
通行证注册
产品答疑
|
网站律师
|
SINA English
违法和不良信息举报电话:4000520066
举报邮箱:jubao@vip.sina.com
Copyright © 1996-2021 SINA Corporation
All Rights Reserved 新浪公司 版权所有
新浪扶翼
行业专区
新浪首页
相关新闻
改版调查
返回顶部